

【ソフトウェアテスト】欠陥分析手法について
「【ソフトウェアテスト】不具合報告のインシデントレポートについて」記事で記載したとおり、インシデントはチケット作成して報告されたのち、内容を分析して対応をし、作成から完了に至るまで管理します。
そうして蓄積されたインシデントレポートは、報告対応されたそのレポート自体が、以降で類似の現象を検出した際の資料として用いられる面もありますが、内容を分析することで、今後の開発品質向上を目指すための判断材料として活用することができます。
いずれのインシデントレポートも、何かしら問題があったから作成されているものであり、問題点は解決した時点で完了とはせずに、内容を振り返って同じ轍を踏まないように以降の活動を随時改善していくことが肝要です。
近年のアジャイル化が進んでいるプロジェクトなどの場合は、直近の開発内容に対するインシデントレポート単体を都度分析するような時間も設けられずに次々進んでいくことがありますが、プロジェクト全体としてインシデントレポートを統合管理し、アジャイル開発の各プロジェクト進行とは別途で機会を設けて、振り返りと共に不具合分析を行うことは、高品質な開発を目指す上で必要な活動です。
ソフトウェア開発現場の現状として、プロジェクト形式もインシデントレポート形式もさまざまある状況なので、欠陥分析の手法もこれが絶対という唯一のものではなく、状況や期間などに合わせて必要な手法でアプローチをすべきです。
統計的内容に基づく分析、インシデントごとの要因に基づく分析、その両面からの分析など、どのような面からアプローチするかによって用いる手法もさまざまあります。
1. 統計的分析

過去に検出されてきた複数のインシデントレポートを定量的に解析して、インシデント発生原因や傾向などを調査し、対策を立てるためのアプローチです。
・信頼度成長曲線
テストで検出するバグの数値に関わる図の表現に信頼度成長曲線(Software Reliability Growth Curve)(ゴンペルツ曲線)があります。ソフトウェア開発における不具合の検出件数は、開発が初期の段階から徐々に増え、開発中期にピークを迎え、開発終了期間が近づくに伴って徐々に収束していく傾向があります。
横軸を期間やテストケースなどのテストの進行度合い、縦軸を検出した不具合の件数として、以下の様な形状のグラフと照らし合わせることで、残りの期間でどの程度の不具合検出が想定されるかを大まかに予測することができます。
※以下の図はあくまでおおよその形状を表現したものです。
ソフトウェア信頼度成長モデルは算出方法によりグラフの形もそれぞれ違います。
参照資料:ソフトウェア信頼度成長モデルに基づく最適リリース問題
https://www.kurims.kyoto-u.ac.jp/~kyodo/kokyuroku/contents/pdf/0680-06.pdf
・信頼度成長曲線のような図
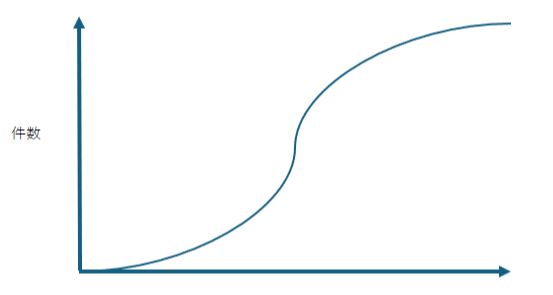
また、プロジェクト全体の現時点での不具合検出状況をグラフ化して上記図と照らし合わせることで、工数の最適化を検討することも可能です。
初期の段階でグラフの線を大きく上回って不具合が検出されている場合は、プロダクト自体の品質が非常に低いという可能性もありますが、設けられた想定テストケース数に対して検出件数が多いと判断されるため、テストケースやテスト人員を削減してコストダウンを狙うことも可能ですし、時間軸に対して大きく下回った状態で進行しているようであれば、テスト工数不足あるいはテスト粒度不足に起因して不具合検出が不十分な可能性もあるため、人員追加やテストケース粒度の見直しが必要になる場合があります。
そもそも開発品質が非常によい場合はいくら工数をかけても不具合検出件数は低くなるため、必ずしもこのグラフから逸れているからといってテストの状況が良くないというわけではないので、あくまでさまざまな判断基準の一つとして参照するものです。
2. 要因ごとの分析

定量的ではなく定性的な観点からインシデント発生の要因を分析するアプローチです。
真因分析と呼ばれます。
真因分析で用いられる手法はさまざまありますが、いずれも定性的アプローチを主体としています。
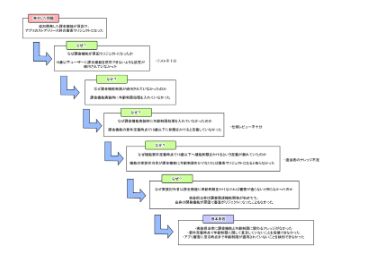
・なぜなぜ分析
トヨタ式なぜなぜ分析とも呼ばれるとおり、自動車メーカーであるトヨタ自動車にて発案された真因分析手法です。
インシデントに対して「なぜ」発生したかを追求することで発生原因の特定につなげます。
追求する回数は5回とされており、おおよそのインシデントは5回の追求で原因が突き止められると考えられています。
課題を明確に記載し、インシデントに対して「なぜ」を問いかけ、特定した原因の解決策を考えるというフローを繰り返して、問題の根本原因を探ります。
主になぜなぜ分析を用いる際には、以下の様な図で表現されます。
・なぜなぜ分析
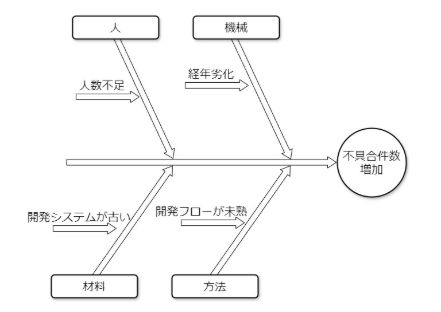
・特性要因図
QC7つ道具とされていた手法のうちの一つです。
(QC7つ道具と新QC7つ道具は別のものであり、特性要因図はQC7つ道具とされています)
魚の骨のような形状で、フィッシュボーン図とも呼ばれます。
複数の原因によって引き起こされるインシデントを大きな枠として結果に置き、そこに関わる複数の要因をそれぞれ特定の集団に分けて表現します。
要因の集団分類は状況によりさまざまですが、主に品質管理の4Mと呼ばれるMan(人)Machine(機械)Material(材料)Method(方法)などで分けられます。
・特性要因図
同じように魚の骨のような図を使用する解析手法に、FTA(故障の木解析)があります。
目的や設定項目など違いがあるため状況により特性要因図とFTA(故障の木解析)で使い分けが必要ですが、魚の骨のような形状の図で結果と要因の因果関係を整理する際に用いられます。
3. ODC分析

ODC(Orthogonal Defect Classification)と呼ばれる手法で、日本語表現では直交欠陥分類と呼ばれます。
インシデント作成の際に、互いに影響しないような属性を設定し、属性を元にして件数や傾向などを分析します。
「Orthogonal Defect Classification v 5.2 for Software Design and code」ドキュメントでは、主に以下8つの属性に分類されます。
・Defact Removal Activities(欠陥検出活動)
・Trigger(トリガー)
・Impact(影響範囲)
・Target(修正対象)
・Defect Type(欠陥タイプ)
・Qualifier(欠陥実装タイプ)
・Age(履歴)
・Source(ソース)
1. Defact Removal Activities(欠陥検出活動)
いつ欠陥を検出したかの属性です。
欠陥は早期に検出できれば開発もテストも品質が高く工数も軽くて済むと見込まれます。
この属性がテストの後半に偏るようであれば、より早期の検出ができるようテストと開発の体制について検討すべきでしょう。
2. Trigger(トリガー)
インシデントの再現性に関わる環境や手順についての属性です。
比較的簡単に再現されるものや、検出されやすい単純なインシデントがテストの後半に検出されるようであれば、テスト粒度について検討し、早期発見を目指すような改善が必要です。
3. Impact(影響範囲)
そのインシデントがシステムやサービスにどの程度影響を与えるかについての属性です。
インシデントレポートに定義される重要度評価と同様の観点ではありますが、致命的なインシデントが多く検出される場合は、開発の体制について検討すべきでしょう。
4. Target(修正対象)
修正対象となった成果物についての属性です。
仕様定義のドキュメントや資料が対象として多く挙げられる場合は、機能実装より前の段階でのテストに重点を置くようにすべきです。
開発品質自体に問題がなくとも仕様参照先資料の品質が悪いと、テストやスケジュール管理に無駄な工数が発生する懸念があります。
5. Defect Type(欠陥タイプ)
修正した欠陥のタイプに関する属性です。
主に修正を担当した人が内容を判断しますが、コード内の関数やクラスやオブジェクトに由来するものか、パラメータや条件に関わるものかなど分析します。
6. Qualifier(欠陥実装タイプ)
実装に際しての問題点に関する属性です。
仕様の勘違いによる「誤り」なのか、実装すべき仕様が漏れていた「漏れ」なのか等を設定します。
7. Age(履歴)
その欠陥がいつ作成されたかに関する属性です。
新規に作成されたものか、リファクタリングなどに関わる変更で作成されたものか、過去に修正した不具合の再発によるものなのか等を設定します。
8. Source(ソース)
欠陥が作成された環境や組織についての属性です。
内製が多数ある場合は自社開発チームに問題がある可能性があり、外部要因が多数ある場合は外部ベンダーに問題がある可能性があります。
上記8属性以外にもチームや組織によって独自に属性を用いたりしますが、定性的な属性の観点から集積した情報を定量的な解析にかけて傾向を分析することで、プロジェクト全体のマクロな視点から、発生原因となっている箇所にフォーカスしたミクロな視点まで、幅広い範囲を網羅した観点で欠陥を分析することができます。