

インデックスとは?メリットデメリットやインデックスの種類も交えてご紹介
インデックスとは、データベースを扱う際には欠かすことのできない概念となります。
インデックスの取り扱いによって、データのアクセス速度が大きく変わります。
特に大規模なデータを扱う場合には、取り扱いに気をつけなくてはなりません。
インデックスを設定した結果、処理速度が遅くなってしまうことやそもそもインデックスを使用するような実行計画が選択されないこともあるのです。
インデックスは、DBMSの種類(例えば、OracleやMySQL、Postgreなど)によっても異なります。
インデックスの仕様を知らないと、開発者にとって意図しない処理をしてしまう可能性もあります。
そこで今回はインデックスについてメリットデメリットや具体的にどのような種類があるのかを説明していきます。
1. インデックスとは

そもそもインデックスとは何かについてまずはご説明します。
インデックスは索引とも呼ばれており、テーブル内の特定の列を識別できる値(キー値)と、キー値によって特定された列のデータが格納されている位置を示すポインタで構成されています。
インデックスを参照することで目的のデータが格納されている位置に直接アクセスすることができ、検索を高速化することができます。
もしインデックスを作成していないテーブルにデータをアクセスする場合は、データを全件検索しなくてはなりません。
これをフルスキャンと呼びますが、その場合データが数千件とかであれば処理速度はそこまで変わりませんが、数千万件や数億件の場合は処理にかなり時間がかかってしまいます。
これでは大量のデータを扱う際に処理ごとに時間がかかってしまい不便なシステムとなってしまいます。
そこでインデックスを作成しておけば、検索処理を実行した際にまずは作成したインデックスを検索し、データが存在する行を素早く発見することができます。
無駄なアクセスを減らすことができるため処理速度を担保することができるのです。
1-1. メリット
インデックスを作成するメリットとしては上記でも述べましたが、やはり検索速度の向上が期待できることです。
大量データを取り扱わなくてはならない場合には必ず必要となる概念です。
データベースは処理速度が命ですので、このメリットを享受できる限り、必ずインデックスを設定する必要があります。
1-2. デメリット
しかし、インデックスを作成するデメリットもあります。
インデックスを作成したテーブルに追加/変更処理を行った場合、そのインデックスにも追加/変更処理を行う必要があります。
それによりオーバーヘッドが発生してしまい、処理速度が遅くなることがあります。
またデータ件数が少なかったり、NULL値を多く含むカラムにもインデックスを作成してしまうと、インデックスがない状態のほうがアクセスが早くなることがあります。
1-3. インデックスを作成する/しない場合
インデックスを作成するべき場合と作成しないほうがいい場合について下記にそれぞれまとめました。
インデックスを作成したほうが良い場合
・テーブルの行数が多い(目安は10万レコード以上)
・select時の回答行が全体の15%程度未満
・検索対象の項目に値の重複、偏りが少ない場合
・表の更新・追加・削除が少ない場合
インデックスを作成する必要がない場合
・テーブルの行数が少ない
・select時の回答行がレコードの大半を占める場合
・検索対象の項目にNULL値を多く含む場合
・表の更新・追加・削除が多い場合
2. インデックスの作成方法と種類

インデックスを作成するにあたって様々な方法があります。
データベースを利用するアプリケーションを開発するシステムエンジニアにとっては、あまり意識することはない方もいるとは思いますが、インデックスを深く理解するためには下記内容も知っておくことで、よりデータベースを理解することができ、インデックスを作成する際に適切なインデックスを選択することができるようになります。
性能のより良いシステムを作成することも可能となります。
2-1. ビットマップインデックス
ビットマップインデックスは、検索に用いられるカラムに対して、その値とレコードとのビットマップを使ってレコードを検索するインデックスです。
該当カラムのデータに対して0または1にて情報を保持しておくものです。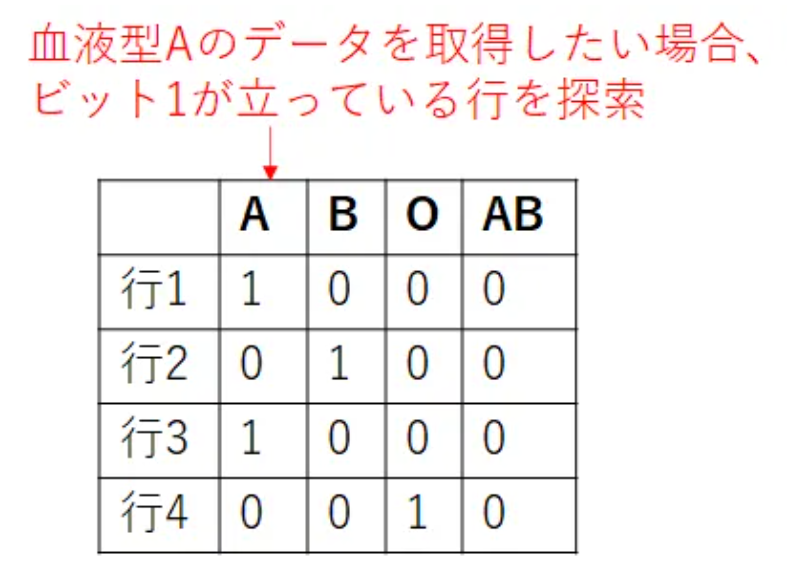
https://products.sint.co.jp/siob/blog/index
ビットマップインデックスを使用するべき場合として「カーディナリティの低いカラムの検索」がまず挙げられます。
カーディナリティとはデータの種類の多さを指す言葉です。
例えば名前の場合、同姓同名の人はかなり少ないので、データパターンとしてはかなり多くなる傾向にあります。
これをカーディナリティが高いと呼びます。
一方性別や血液型などはデータパターンがかなり限定されており、これをカーディナリティが低いと呼びます。
ビットマップインデックスは性別や血液型などのカラムに設定するのが有用となります。
また、OR条件を選択した場合でもビットマップインデックスであればそのままインデックスが実行計画に選択されることが多くなりますので、メリットに挙げられます。
一方、ビットマップインデックスを使用するべきでない場合として頻繁にデータの登録や更新、削除が発生する場合です。
この場合は処理中に大量のデータがロックされてしまうため、性能劣化の危険が高まります。
またカーディナリティが高いカラムの場合は後述するBツリーインデックスがオススメとなります。
2-2. Bツリーインデックス
Bツリーインデックスとは、ソート処理と木構造によって検索の高速化をするアルゴリズムです。
このBツリー構造がDBのインデックスの内部構造となります。
Oracleではインデックスを作成する際にこのBツリーがデフォルトの設定になっており広く使われているインデックスとなります。
アクセスしたいデータに対して、木構造内のデータに対する大小を判定して、ルートノードやブランチノードを経てリーフノードにたどり着きます。
該当するリーフノードにたどり着いた場合、そのリーフノードには該当するレコードのポインタ情報が登録されておりアクセスすることができます。
下記画像ではBツリー+インデックスと呼ばれているものです。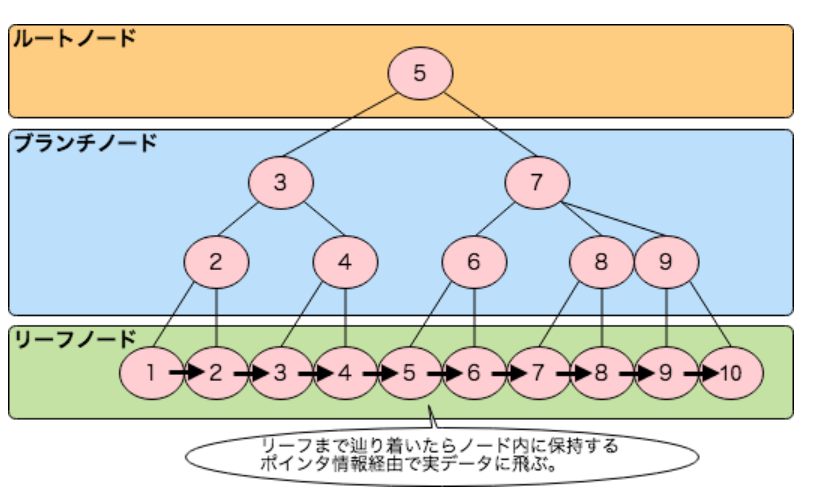
https://devblog.thebase.in/entry/2018/12/09/110000
「カーディナリティの高いカラムの検索」に向いております。
その場合は木構造での検索が有効に働き、かつリーフノード内の該当するレコードのポインタ情報が少ないのでBツリーインデックスの場合はかなり検索速度の向上を見込むことができます。
3. まとめ

今回はインデックスとは何か?というところからよく使われているインデックスについて紹介していきました。
インデックスは大量のデータを扱う上では必須となる概念である一方、取り扱いを間違えてしまうと予期しない実行計画によってアクセス速度が劣化してしまう危険性もあります。
また使用するDBMSによっても仕様が異なるため、データ分布などをまずは想定、分析を行い、それから使用するインデックスを選定する必要があります。
これらは知っておく必要があるので、今後もし知らなければ本記事をきっかけに勉強して大規模なプロジェクトに備えましょう。