

【初心者用】SQLのテーブル取得について色々操作をしてみた
公開日: 2022/6/23 更新日: 2022/6/14
SQLには色々なテーブル取得の方法がある。
今回は、実際の現場で使用されることが想定されるSQLのデータ取得について操作をしながら学んでいく。
https://style.potepan.com/articles/27029.html
SQL BETWEEN演算子の構文と使い方 データを範囲指定して抽出する
https://tech.pjin.jp/blog/2020/12/28/%E3%80%90sql%E5%85%A5%E9%96%80%E3%80%91in%E6%BC%94%E7%AE%97%E5%AD%90%E3%81%AB%E3%82%88%E3%82%8B%E6%9D%A1%E4%BB%B6%E6%8C%87%E5%AE%9A/
SQL基礎 IN演算子に夜条件指定
https://tech.pjin.jp/blog/2020/12/25/%E3%80%90sql%E5%85%A5%E9%96%80%E3%80%91like%E6%BC%94%E7%AE%97%E5%AD%90%E3%81%AB%E3%82%88%E3%82%8B%E6%9D%A1%E4%BB%B6%E6%8C%87%E5%AE%9A/
SQL基礎 LIKE演算子による条件指定
https://www.sejuku.net/blog/72923
SQL GROUP BYで自在に集計! 集計関数やHAVINGと合わせて使おう
https://www.sejuku.net/blog/72918
SQLで並び替え! ORDER BYを基礎から応用まで学ぼう
https://www.sejuku.net/blog/54990
SQL入門 DISTINCTで重複行をまとめる方法
今回は、実際の現場で使用されることが想定されるSQLのデータ取得について操作をしながら学んでいく。
参考サイト
指定した値の範囲と比較する(BETWEEN演算子)https://style.potepan.com/articles/27029.html
SQL BETWEEN演算子の構文と使い方 データを範囲指定して抽出する
https://tech.pjin.jp/blog/2020/12/28/%E3%80%90sql%E5%85%A5%E9%96%80%E3%80%91in%E6%BC%94%E7%AE%97%E5%AD%90%E3%81%AB%E3%82%88%E3%82%8B%E6%9D%A1%E4%BB%B6%E6%8C%87%E5%AE%9A/
SQL基礎 IN演算子に夜条件指定
https://tech.pjin.jp/blog/2020/12/25/%E3%80%90sql%E5%85%A5%E9%96%80%E3%80%91like%E6%BC%94%E7%AE%97%E5%AD%90%E3%81%AB%E3%82%88%E3%82%8B%E6%9D%A1%E4%BB%B6%E6%8C%87%E5%AE%9A/
SQL基礎 LIKE演算子による条件指定
https://www.sejuku.net/blog/72923
SQL GROUP BYで自在に集計! 集計関数やHAVINGと合わせて使おう
https://www.sejuku.net/blog/72918
SQLで並び替え! ORDER BYを基礎から応用まで学ぼう
https://www.sejuku.net/blog/54990
SQL入門 DISTINCTで重複行をまとめる方法
1. BETWEEN演算子
BETWEEN演算子は、指定のカラムの値が範囲に含まれているかどうか調べることができる。
実際に操作をしてみる。
今回も復習をかねて新しいテーブルから作成する。
humanテーブルを作成する。
create table human (id int(10), name varchar(20), age int(10), area varchar(20));
idカラム、 nameカラム、 ageカラム、 areaカラムを作成。
humanテーブルにデータを追加していく。
insert into human (id, name, age, area) values (1, '鈴木次郎', 32, '愛知県'), (2, '平山智', 29, '香川県'), (3, '佐藤花子', 31, '石川県'), (4, '田沢英二', 33, '東京都');

select * from human where age between 31 and 32;

between演算子を使用して指定の範囲のデータを取得することができた。
実際に操作をしてみる。
今回も復習をかねて新しいテーブルから作成する。
humanテーブルを作成する。
create table human (id int(10), name varchar(20), age int(10), area varchar(20));
idカラム、 nameカラム、 ageカラム、 areaカラムを作成。
humanテーブルにデータを追加していく。
insert into human (id, name, age, area) values (1, '鈴木次郎', 32, '愛知県'), (2, '平山智', 29, '香川県'), (3, '佐藤花子', 31, '石川県'), (4, '田沢英二', 33, '東京都');
humanテーブルを作成
ではwhere句で条件を絞り、 BETWEEN句で ageカラムが 31から32までのデータを取得。select * from human where age between 31 and 32;
between演算子を使用して指定の範囲のデータを取得することができた。
2. IN演算子
IN演算子を使用すると、カラムの値が指定したリストのいずれかと一死するかどうか調べることができる。
では先程のhumanテーブルを使用してデータを抽出してみる。
select * from human where area in ('愛知県', '東京都');

IN演算子を使用して、 areaカラムが、 愛知県と東京都のデータを取得することができた。
では、もう少しデータを追加して再度抽出してみる 。

not in演算子を使用する。
select * from human where area not in ('愛知県', '東京都', '大阪府');

愛知県、東京都、大阪府以外のデータを取得することができた。
このように WHERE句で条件指定して、IN演算子を使用することで 対象のデータを取得することができる。
では先程のhumanテーブルを使用してデータを抽出してみる。
select * from human where area in ('愛知県', '東京都');
IN演算子を使用して、 areaカラムが、 愛知県と東京都のデータを取得することができた。
では、もう少しデータを追加して再度抽出してみる 。
humanテーブル
areaカラムが 愛知県でも東京都でも、大阪府でもない条件で抽出する。not in演算子を使用する。
select * from human where area not in ('愛知県', '東京都', '大阪府');
愛知県、東京都、大阪府以外のデータを取得することができた。
このように WHERE句で条件指定して、IN演算子を使用することで 対象のデータを取得することができる。
3. LIKE演算子
LIKE演算子は、文字列などの部分一致で検索をしてデータを取得することができる。
例えば、データベースの中から都道府県の府のついた都道府県を抽出したい時など、特定の地域に住んでいる従業員だけを抽出したい時などに利用される。
では先程のhumanテーブルで LIKE演算子を使用してみる。
humanテーブルにデータを追加する。
insert into human (id, name, age, area) values (7, '大森慎吾', 28, '京都府');
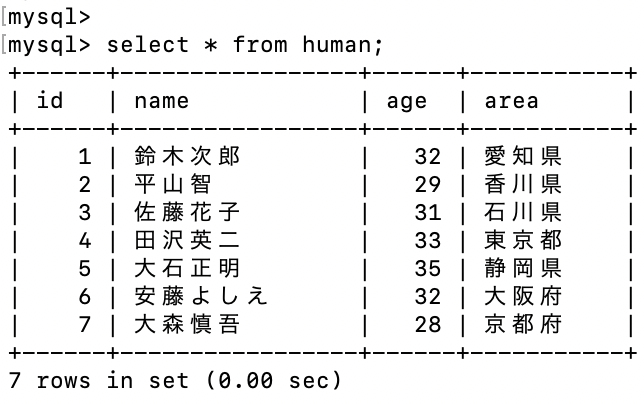
humanテーブルに新しいデータを追加。
LIKE演算子を使用して、areaカラムに 府がついた都道府県を検索する。
select * from human where area like '%府';

areaカラムに 府が末尾についたデータを取得することができた。
このように「文字列%」とすることで前方一致でデータを検索することができる。
中間一致検索をしてみる。
areaカラムで 文字と文字の間に川が入っている都道府県を検索する。
select * from human where area like '_%川%_';

このようにareaカラムの名前の中間が 川のデータのみを取得することができた。
select * from human where name like '%大%';

nameカラムに 大 がついているデータを抽出することができた。
例えば、データベースの中から都道府県の府のついた都道府県を抽出したい時など、特定の地域に住んでいる従業員だけを抽出したい時などに利用される。
では先程のhumanテーブルで LIKE演算子を使用してみる。
humanテーブルにデータを追加する。
insert into human (id, name, age, area) values (7, '大森慎吾', 28, '京都府');
humanテーブルに新しいデータを追加。
LIKE演算子を使用して、areaカラムに 府がついた都道府県を検索する。
select * from human where area like '%府';
areaカラムに 府が末尾についたデータを取得することができた。
このように「文字列%」とすることで前方一致でデータを検索することができる。
中間一致検索をしてみる。
areaカラムで 文字と文字の間に川が入っている都道府県を検索する。
select * from human where area like '_%川%_';
このようにareaカラムの名前の中間が 川のデータのみを取得することができた。
部分一致検索
nameカラムに 大 が含まれるデータを検索する。select * from human where name like '%大%';
nameカラムに 大 がついているデータを抽出することができた。
4. データをグループ化する GROUP BY
では次にデータをグループ化する GROUP BY句を操作していこう。
GROUP BY句は、データのグループ化を行うときに使用する。
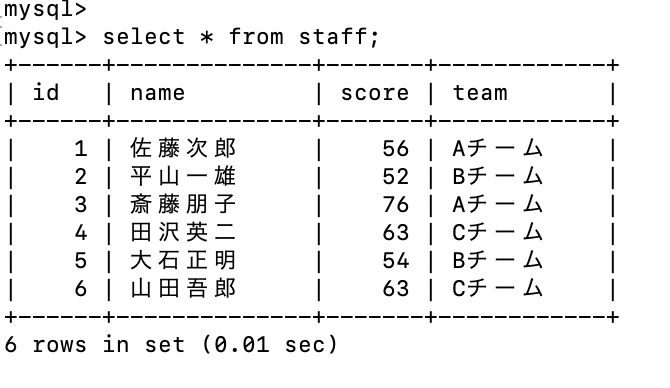
staffテーブルを作成する。
create table staff (id int(10), name varchar(20), score int(10), team varchar(10));
idカラム、 nameカラム、 scoreカラム、 teamカラムを作成する
チーム数をカウントする。
select team, count(team) from staff group by team;

それぞれチームごとにグループ化してチーム数をカウントすることができた。
次にチームごとにグループ化してチームごとの scoreカラムの平均値を取得する。
構文
SELECT AVG(カラム名) FROM テーブル名 GROUP BY カラム名
select avg(score) from staff group by team;
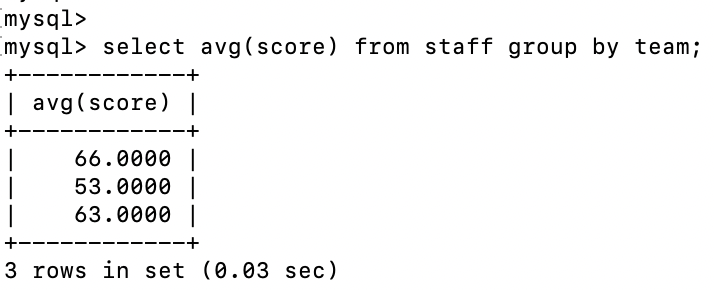
avg関数を使用してグループごとの平均値を取得することができた。
では次に sum関数を使用してグループごとに合計値を取得する。
select sum(score) from staff group by team;
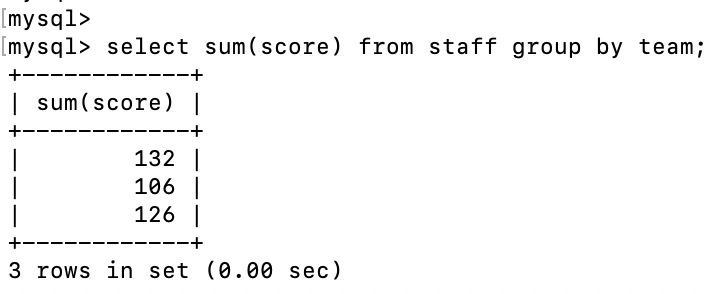
グループごとの合計値を取得することができた。
このようにGROUP BY句を使用して、グループ化するときは、 AVG関数やSUM関数などの集計関数と一緒に使うことが多い。
GROUP BY句は、データのグループ化を行うときに使用する。
では実際に操作をしてみよう
今回は、新しいテーブルを作成する。staffテーブルを作成する。
create table staff (id int(10), name varchar(20), score int(10), team varchar(10));
idカラム、 nameカラム、 scoreカラム、 teamカラムを作成する
データを追加
insert into staff values (1, '佐藤次郎', 56, 'Aチーム'), (2, '平山一雄', 52, 'Bチーム'), (3, '斎藤朋子', 76, 'Aチーム'), (4, '田沢英二', 63, 'Cチーム'), (5, '大石正明', 54, 'Bチーム'), (6, '山田吾郎', 63, 'Cチーム');
staffテーブルを作成
ではここからチームごとにグループ化をする。チーム数をカウントする。
select team, count(team) from staff group by team;
それぞれチームごとにグループ化してチーム数をカウントすることができた。
次にチームごとにグループ化してチームごとの scoreカラムの平均値を取得する。
構文
SELECT AVG(カラム名) FROM テーブル名 GROUP BY カラム名
select avg(score) from staff group by team;
avg関数を使用してグループごとの平均値を取得することができた。
では次に sum関数を使用してグループごとに合計値を取得する。
select sum(score) from staff group by team;
グループごとの合計値を取得することができた。
このようにGROUP BY句を使用して、グループ化するときは、 AVG関数やSUM関数などの集計関数と一緒に使うことが多い。
5. 条件を指定してグループ化する場合
HAVING句やWHERE句を使用して、条件を指定してグループ化をする場合。
staffテーブルに新しいデータを追加。
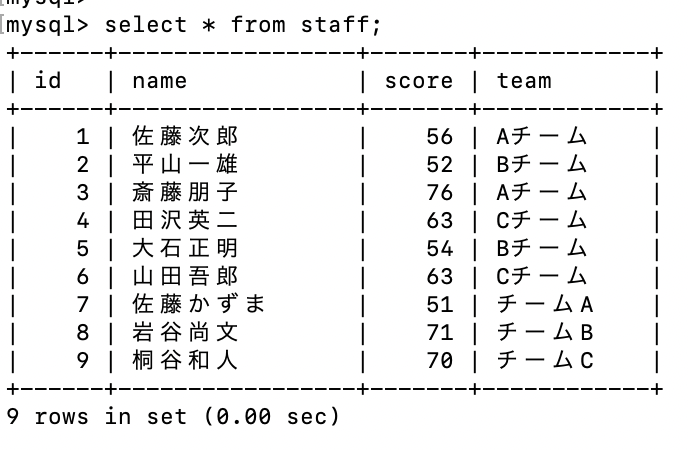
staffテーブルに新しいデータを追加したが、新しく追加したteamカラムのデータの名前が異なっていたため、上書きする。
データを上書きたい場合は、UPDATE文を使用する。
UPDATE文の構文
UPDATE テーブル名 SET 更新する内容 WHERE 条件式
id = 7の teamカラムを Aチームに変更する場合
update staff set team = 'Aチーム' where id = 7;
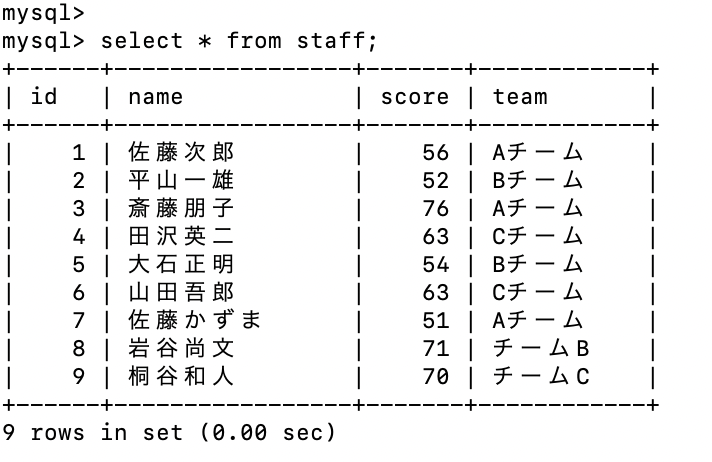
id = 7 の teamカラムを Aチーム に上書きすることができた。
同じように id = 8, id = 9 のデータも変更する。
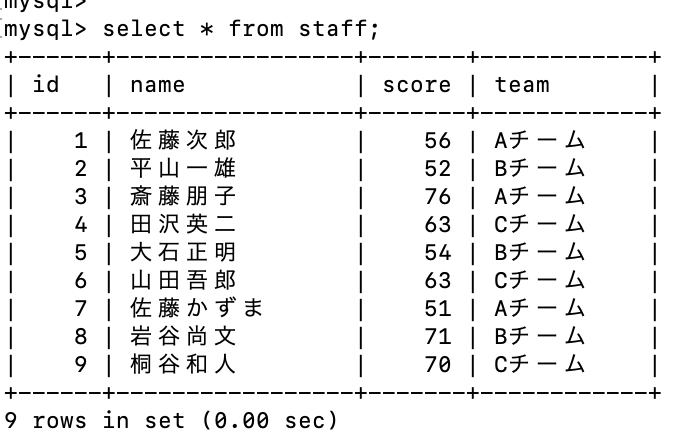
データを更新することができた。
ではHAVING句を使い、scoreカラムの平均値が60以上のデータだけを取得する。
select team, avg(score) from staff group by team having avg(score) >=60;
having句を使い平均値が60以上のグループだけを取得する。

今回 60以上の平均値は、 AチームとBチームだけを取得することができた。
このように HAVING句を使い、グループ化することで、条件を設定してデータを取得することができた。
それぞれのチームの平均値を確認する。
select team, avg(score) from staff group by team;
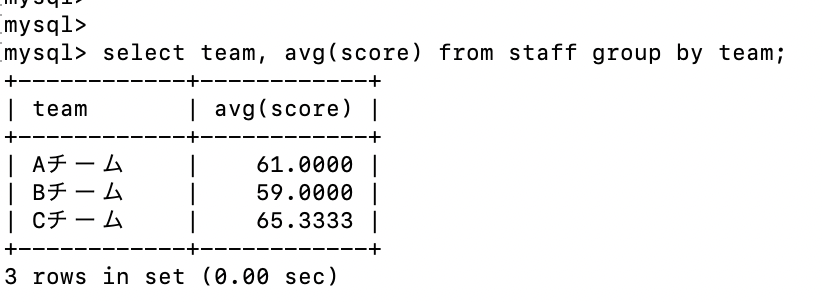
合わせてチームごとの合計値が180を超えるデータだけを取得してみる。
select team, sum(score) from staff group by team having sum(score) >= 180;

teamカラムをグループ化して、グループ化したデータを scorカラムが 180以上のデータだけを取得した。
AS句を使用すると、別名のカラムに割り当てることができる。
今回は、グループ化した後に、AS句で別名を割り当て、HAVING句で条件を設定してデータを取得してみる
avg関数で scoreの平均値を取得して 、取得した平均値のカラムを avg_score カラムにして、グループ化をする
select team, avg(score) as avg_score from staff group by team;

チームごとにグループ化して、チームごとの平均値を取得した上で、 カラム名を avg_score に変更することができた
staffテーブルに新しいデータを追加。
staffテーブルに新しいデータを追加したが、新しく追加したteamカラムのデータの名前が異なっていたため、上書きする。
データを上書きたい場合は、UPDATE文を使用する。
UPDATE文の構文
UPDATE テーブル名 SET 更新する内容 WHERE 条件式
id = 7の teamカラムを Aチームに変更する場合
update staff set team = 'Aチーム' where id = 7;
id = 7 の teamカラムを Aチーム に上書きすることができた。
同じように id = 8, id = 9 のデータも変更する。
データを更新することができた。
ではHAVING句を使い、scoreカラムの平均値が60以上のデータだけを取得する。
select team, avg(score) from staff group by team having avg(score) >=60;
having句を使い平均値が60以上のグループだけを取得する。
今回 60以上の平均値は、 AチームとBチームだけを取得することができた。
このように HAVING句を使い、グループ化することで、条件を設定してデータを取得することができた。
それぞれのチームの平均値を確認する。
select team, avg(score) from staff group by team;
合わせてチームごとの合計値が180を超えるデータだけを取得してみる。
select team, sum(score) from staff group by team having sum(score) >= 180;
teamカラムをグループ化して、グループ化したデータを scorカラムが 180以上のデータだけを取得した。
AS句を使用して別名で割り当て
AS句を使用すると、別名のカラムに割り当てることができる。
今回は、グループ化した後に、AS句で別名を割り当て、HAVING句で条件を設定してデータを取得してみる
avg関数で scoreの平均値を取得して 、取得した平均値のカラムを avg_score カラムにして、グループ化をする
select team, avg(score) as avg_score from staff group by team;
チームごとにグループ化して、チームごとの平均値を取得した上で、 カラム名を avg_score に変更することができた
6. 取得するデータをソートするORDER BY句
データをソートしたい場合は、ORER BY句を使用する
復習もかねて新しいテーブルを作成する
user2テーブルを作成
create table user2 (id int(10), name varchar(20), age int(10));
idカラム、 nameカラム、 ageカラムを作成

user2テーブルを作成
order by句を使って、データをソートしてみる
ageカラムをソートする
select * from user2 order by age asc;

ageカラムを昇順にソートすることができた
次はageカラムを降順(desc)に取得する
select * from user2 order by age desc;

降順に取得することができた
WHERE句を使用して条件を指定してソートする
ageカラムが30より大きいデータを取得して、idカラムを降順にする場合
select * from user2 where 30 < age order by id desc;

where句で条件を設定して、ソートをかけることができた
復習もかねて新しいテーブルを作成する
user2テーブルを作成
create table user2 (id int(10), name varchar(20), age int(10));
idカラム、 nameカラム、 ageカラムを作成
データを追加していく
insert into user2 (id, name, age) values (1, '鈴木一郎', 32), (2, '佐藤英二', 33), (3, '加藤吾郎', 33), (4, '山崎誠子', 28), (5, '平山次郎', 29);
user2テーブルを作成
order by句を使って、データをソートしてみる
ageカラムをソートする
select * from user2 order by age asc;
ageカラムを昇順にソートすることができた
次はageカラムを降順(desc)に取得する
select * from user2 order by age desc;
降順に取得することができた
WHERE句を使用して条件を指定してソートする
ageカラムが30より大きいデータを取得して、idカラムを降順にする場合
select * from user2 where 30 < age order by id desc;
where句で条件を設定して、ソートをかけることができた
7. 取得するデータの行数の上限を設定する
LIMIT句を使用すると取得するデータの行数の上限を設定することができる
先程の user2テーブルを使い操作してみる

user2テーブル
ageカラムを基準に昇順に並べ、LIMIT句を使用してデータを3行文取得する
select * from user2 order by age limit 3;

ageカラムを昇順にして、LIMIT句で3行分のデータを取得することができた
先程の user2テーブルを使い操作してみる
user2テーブル
ageカラムを基準に昇順に並べ、LIMIT句を使用してデータを3行文取得する
select * from user2 order by age limit 3;
ageカラムを昇順にして、LIMIT句で3行分のデータを取得することができた
8. 重複データを除外してデータを取得する DISTINCT句
DISTINCT句を使うと、重複したデータを除外して1つにまとめることができる
user2テーブルに新しいデータを追加する
insert into user2 (id, name, age) values (6, '鈴木一郎', 32), (7, '佐藤英二', 33), (8, '平山次郎', 29);
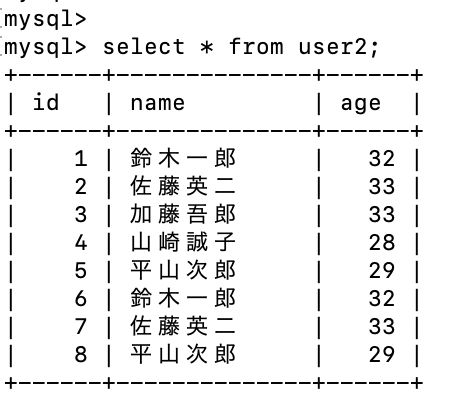
nameカラムと、 ageカラムに重複したデータを追加した
まず nameカラムと ageカラムを取得する
select name, age from user2;

重複したデータを除外してこのテーブルから nameカラムと ageカラムを取得する
select distinct name, age from user2;

distinct句を使い、重複した nameカラムと、 ageカラムを除外して取得することができた
次に重複したデータを省いてCOUNT関数で何行分あるか確かめてみる
select count(distinct name, age) from user2;

重複した行を省いてカウントすることができた
user2テーブルに新しいデータを追加する
insert into user2 (id, name, age) values (6, '鈴木一郎', 32), (7, '佐藤英二', 33), (8, '平山次郎', 29);
nameカラムと、 ageカラムに重複したデータを追加した
まず nameカラムと ageカラムを取得する
select name, age from user2;
重複したデータを除外してこのテーブルから nameカラムと ageカラムを取得する
select distinct name, age from user2;
distinct句を使い、重複した nameカラムと、 ageカラムを除外して取得することができた
次に重複したデータを省いてCOUNT関数で何行分あるか確かめてみる
select count(distinct name, age) from user2;
重複した行を省いてカウントすることができた
9. まとめ
ここまでデータベースの色々なデータの取得方法について操作をしてみた。
実際の現場では色々な条件でデータを取得して開発やテスト業務を行っていくことが想定されるため、データの取得について何回も練習して操作に慣れていくことが大事なので、毎日SQLを操作して、少しずつ操作に慣れていく。
実際の現場では色々な条件でデータを取得して開発やテスト業務を行っていくことが想定されるため、データの取得について何回も練習して操作に慣れていくことが大事なので、毎日SQLを操作して、少しずつ操作に慣れていく。