

データ操作文(DML)を使ったデータ操作の基本
業務では、テーブルに対して何らかのデータを追加したり、変更、削除を行うことがあります。
ここでは、その操作で使用するINSERT文やUPDATE文などについて記載しています。
1. データ操作

テーブルに対して何かしらのデータを追加したり、更新、削除を行う場合があります。
その際に使用するSQL文をデータ操作文(DML)と呼びます。
主に使用されるINSERT文、UPDATE文、DELETE文、MERGE文について記載します。
1-1. INSERT
指定したテーブルに対して新しいレコードを追加する処理を行います。
INSERT文では、データを追加するカラムを指定する方法と指定しない方法で記述する際の注意点が異なります。
・INSERT文でカラムを指定する場合
カラムを指定する場合の構文は、次の通りになります。INSERT INTO <テーブル名> ( <カラム名1>, <カラム名2>, …)
VALUES ( <値1>, <値2>, …);カラムを指定する場合の注意点は、次の通りになります。
・<テーブル名>の後に値を設定するカラムを指定します。
・指定したカラムの数だけVALUES句の後に値を指定します。
・<テーブル名>とVALUES句の値の並び順は紐づいています。
・対象テーブルの全てのカラムを指定する必要はありません。
・指定しなかったカラムにはNULLまたはカラムのデフォルト値が設定されます。
・INSERT文でカラムを指定しない場合
カラムを指定する場合の構文は、次の通りになります。INSERT INTO <テーブル名>
VALUES ( <値1>, <値2>, …);カラムを指定しない場合の注意点は、次の通りになります。
・VALUES句に対象テーブルに存在するカラム数分の値を設定する必要があります。
・設定する値はテーブルのカラム順に設定する必要があります。
・複数のレコードをまとめて追加
複数のレコードをまとめて追加する場合は、VALUES句に「( <値1>, <値2>, …)」を複数記述します。カラムを指定する場合、指定しない場合の両方でVALUES句以下の書き方は同様です。
例として、3レコードを追加する場合の構文は、次の通りになります。
INSERT INTO <テーブル名> ( <カラム名1>, <カラム名2>, …) VALUES
( <値1>, <値2>, …),
( <値3>, <値4>, …),
( <値5>, <値6>, …);・よく起こるエラー
INSERT文の実行でよく起こるエラーとして、次のようなものがあります。■列と値の数が不一致
カラムを指定する場合、指定しない場合の両方で発生する可能性があります。
カラムを指定する場合では、テーブル名の後にカラムを5つ指定したが、VALUES句で値を3つしか指定しなかったため、エラーが発生しデータの追加に失敗します。
カラムを指定しない場合では、対象テーブルにカラム数が5つありますが、VALUES句で値を3つしか指定しなかったため、エラーが発生しデータの追加に失敗します。
■対象カラムのデータ型と値のデータ型が不一致
データを追加するカラムと追加する値のデータ型が一致していない場合は、エラーとなりデータの追加に失敗します。
また、暗黙的データ型変換ができない場合も同様にエラーとなります。
■NOT NULL制約が設定されたカラムにNULLを設定
NOT NULL制約が設定されたカラムには、NULLを設定することが許可されていないため、NULLを設定することができません。
NULLを設定した場合には、エラーとなりデータの追加に失敗します。
■主キー制約に違反する値を設定
主キー制約が設定されたカラムには、重複した値を設定することができません。
重複した値を設定した場合には、エラーとなりデータの追加に失敗します。
1-2. マルチテーブルINSERT
ただし、レコードを追加できるのは、テーブルのみになるため、ビューなどを追加することはできません。
マルチテーブルINSERTは、次の3つに分類されます。
・無条件INSERT
・条件付きINSERT ALL
・条件付きINSERT FIRST
・無条件INSERT
サブクエリから返された各レコードのINTO句で指定したテーブルに追加されます。・SELECT文のサブクエリの結果をINTO句で指定した全てのテーブルに追加されます。
・INTO句は複数指定できます。
・VALUES句にはカラム名やリテラルを指定できます。
・サブクエリが返すカラム数と対象テーブルのカラム数が同じ場合はVALUES句を省略できます。
・前述の「INSERT文でカラムを指定しない場合」と同様の動作になるため、VALUES句に指定するカラム(リテラル)数が過不足の場合は、エラーとなります。
無条件INSERTを行う構文は、次の通りです。
INSERT ALL
INTO <テーブル名> VALUES (...)
INTO <テーブル名> VALUES (...)
SELECT …;例として、SELECT文でテーブルAのデータを抽出して、テーブル1とテーブル2にデータを追加するとします。
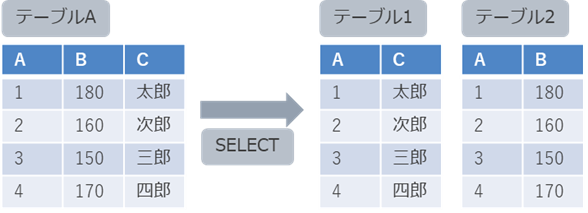
その場合のINSERT文の記述は、次の通りになります。
これにより、テーブル1には、テーブルAのAとCカラムの値が追加され、テーブル2には、テーブルAのAとBの値が追加されます。
INSERT ALL
INTO テーブル1 VALUES (A, C)
INTO テーブル2 VALUES (A, B);
SELECT A, B, C FROM テーブルA;ただし、以下のようにVALUES句に指定するカラム(リテラル)数が過不足の場合は、エラーになるため注意が必要です。
NULLを指定するか、リテラルを指定することでエラーを回避できます。
INSERT ALL
INTO テーブル1 VALUES (A, C)
INTO テーブル2 VALUES (A, B);
SELECT A, B, C FROM テーブルA;テーブル3には、A,B,Dの3カラムありますが、VALUES句に2カラムしか記述していない場合などエラーになります。
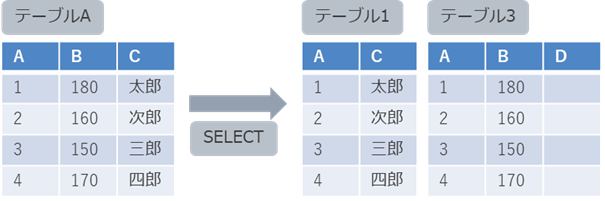
・条件付きINSERT
WHEN句に条件を指定して条件を満たす場合にWHEN句内で指定したテーブルにデータが追加されます。・条件付きINSERTには、INSERTの後に「ALL」か「FIRST」を指定します。
・SELECT文のサブクエリが返す結果がWHEN句に指定した条件を満たす場合に、WHEN句内に指定したテーブルにデータが追加されます。
・1つのWHEN句内に複数のINTO句を指定できます。
・全てのWHEN句の条件を満たさない場合は、ELSE句に指定したテーブルにデータが追加されます。ELSE句は、省略可能です。
・VALUES句にはカラム名やリテラルを指定できます。
・サブクエリが返すカラム数と対象テーブルのカラム数が同じ場合はVALUES句を省略できます。
・前述の「INSERT文でカラムを指定しない場合」と同様の動作になるため、VALUES句に指定するカラム(リテラル)数が過不足の場合は、エラーとなります。
条件付きINSERTを行う構文は、次の通りです。
INSERT ALL
WHEN <条件1> THEN
INTO <テーブル名> VALUES (...)
WHEN <条件2> T1-3. UPDATE
UPDATE文の構文は、次の通りになります。
UPDATE <テーブル名>
SET <カラム名1> = <値>, <カラム名2> = <値>, …
[ WHERE <条件式> ];・UPDATE文では、SET句の後に更新するカラム名と値を指定します。
・更新するカラム名と値を「,(カンマ)」で区切ると複数指定できます。
・WHERE句を指定すると条件を満たすレコードのSET句で指定したカラムの更新処理が行われます。
・WHERE句を省略すると全てのレコードを対象にSET句で指定したカラムの更新処理が行われます。
・SET句には、計算式を指定することもできます。
1-4. DELETE
UPDATE文の構文は、次の通りになります。
DELETE FROM <テーブル名> [ WHERE <条件式> ];・DELETE文では、FROMを省略できます。
・WHERE句を指定すると条件を満たすレコードのみを削除します。
・WHERE句を省略すると全てのレコードを削除します。
1-5. MERGE
MERGE文の構文は、次の通りになります。
MERGE INTO <ターゲットテーブル>
USING ( <ソーステーブル> )
ON ( <条件> )
WHEN MATCHED THEN
UPDATE SET <カラム名> = <値>, ...
[ WHERE <条件式> ]
WHEN NOT MATCHED THEN
INSERT [ (カラム名), ....]
VALUES ( <値>, ... )
[ WHERE <条件式> ];・INTO句に更新(追加)の対象になるテーブル名を指定します。(ターゲットテーブル)
・USING句に参照するテーブル名を指定します。テーブル以外にもビューやサブクエリを指定することもできます。(ソーステーブル)
・ON句にターゲットテーブルとソーステーブルを紐づける条件を指定します。
・ON句に指定したカラムは、WHEN MATCHED句の更新処理では更新できません。
・ON句に指定した条件を満たすレコードの場合、更新処理が行われます。WHERE句が指定されている場合は、WHERE句の条件を満たす場合のみ更新処理が行われます。
・WHEN MATCHED句を省略することができます。省略した場合は、更新処理は行われません。
・ON句に指定した条件を満たさないレコードの場合、WHEN NOT MATCHED句に指定した追加処理が行われます。
WHERE句が指定されている場合は、WHERE句の条件を満たす場合のみ更新処理が行われます。
・WHEN NOT MATCHED句を省略することができます。省略した場合は、更新処理は行われません。
例として、以下のイメージの左側の通りにターゲットテーブルとソーステーブルがあった場合にMERGE文を実行したら右側の実行結果のテーブルのように処理が行われます。

2. シーケンスと索引

テーブルに格納されているデータを効率的に検索するために行う索引、レコードに連番を指定するシーケンスについて記載します。
2-1. 索引とは
テーブルからのデータ読み取り速度を高速化するオブジェクトになります。
検索条件に含まれるテーブルのカラムに索引(インデックス)を作成することで、検索条件に一致するレコードを高速に得ることができます。
例としては、本の索引に例えて説明されることがあるかと思います。
本の中から特定の用語を探す際に、先頭ページから探した場合は見つけるまでに時間がかかりますが、索引から探した場合は早く該当のページを見つけることができます。
しかしながら、索引を作成しても高速化できない場合があります。
その1つが、検索でヒットするデータの件数が多い場合は、索引による高速化の効果があまりありません。
そのため、検索でヒットするデータの件数が少ない場合には、効力がありますが、多い場合には、索引を使用せず検索した方が早い場合があります。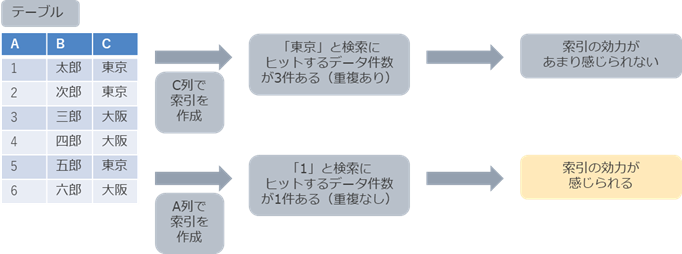
2-2. 索引の作成
CREATE [UNIQUE] INDEX <索引名> ON <テーブル名> ( <カラム名1>, <カラム名2>, …) ;・索引列(索引を設定するカラム)は、WHERE句の条件として頻繁に使用するカラムを指定することが推奨されます。
・CREATE文に「UNIQUE」を指定すると一意索引が作成されます。
・一意索引と非一意索引
一意索引と非一意索引は、索引列に指定した値に重複が含まれている(値が一意でない)場合に非一意索引と呼ばれます。値に重複が含まれていない(値が一意)場合は一意索引と呼ばれています。
索引を作成する場合には、非一意索引で作成することが多いかと思います。
なぜなら、索引に指定するカラムには、主キー制約や一意制約を行っている場合があり、これによって一意索引が自動的に作成されます。
そのため、業務などでは、非一意索引で作成することが多いかと思います。
3. 索引の削除
DROP INDEX <索引名>;3-1. シーケンスとは
主キーや一意キーとなるカラムは、テーブルに格納されたレコードを識別するためのカラムとして使用されるため、一意の値を設定する必要があります。
よくある対応として、連番を設定してカラムの値を一意にすることがあります。
この連番を設定する処理をシーケンスを使うことで簡単に行うことができます。
3-2. シーケンスの作成
CREATE SEQUENCE <シーケンス名>
[ START WITH <初期値> ]
[ INCREMENT BY <増分値> ]
[ MAXVALUE <最大値> ]
[ CYCLE | NOCYCLE ]
[ CACHE <キャッシュ数> | NOCACHE ];・CYCLEを指定すると、シーケンスが最大値に達した後に初期値から再度シーケンスが作成されます。
・NOCYCLEを指定すると、シーケンスが最大値に達するとそれ以上は作成されません。
・CACHEは、メモリ上で保持しておくシーケンスの値の数を指定します。
・NOCACHEを指定すると、メモリ上でシーケンスの値を保持しません。
・作成するシーケンスのデフォルトは、次の通りです。
・・・初期値:1、
・・・増分値:1、
・・・最大値なし、
・・・NOCYCLE、
・・・CACHEは20
3-3. シーケンスの使用例
・使用例1:連番を振り出す
レコードを追加する際に新しく連番を取得してカラムの値として使用します。新しく連番を振り出すには、NEXTVALを使用します。
レコード追加時の使用例は、次の通りになります。
INSERT INTO <テーブル名> (SEQNO, <カラム名1>, <カラム名2>, …)
VALUES (<シーケンス名>.NEXTVAL <値1>, <値2>, …);・使用例2:振り出された連番を確認
すでに振り出されている連番を確認するには、CURRCALを使用します。連番を確認する時の使用例は、次の通りになります。
SELECT <シーケンス名>.CURRVAL FROM dual;3-4. シーケンスの削除
DROP SEQUENCE <シーケンス名>;4. ビュー
ビューは実際にはデータを持っていない仮想的なテーブルです。
仮想表とも呼ばれています。
ビューに対してSELECT文を発行すると、ビューに定義されたSELECT文が実行されその結果を参照することができます。
そのため、ビューは「SELECT文に名前を付けて保存したもの」と捉えることができます。
複雑なSQL文もビューとして定義しておくことで、毎回SQLを作成する必要がなくなり作成済みのSQL文を実行できるため、効率よく作業が行えるようになります。